
4 Applications of Pseudonymisation Technique
Pseudonymisation as a battle-tested data privacy protection technique is usually applied in four ways.
Suppression
Suppression is removing certain data elements since that combination is rare and is at risk of reidentifying. 
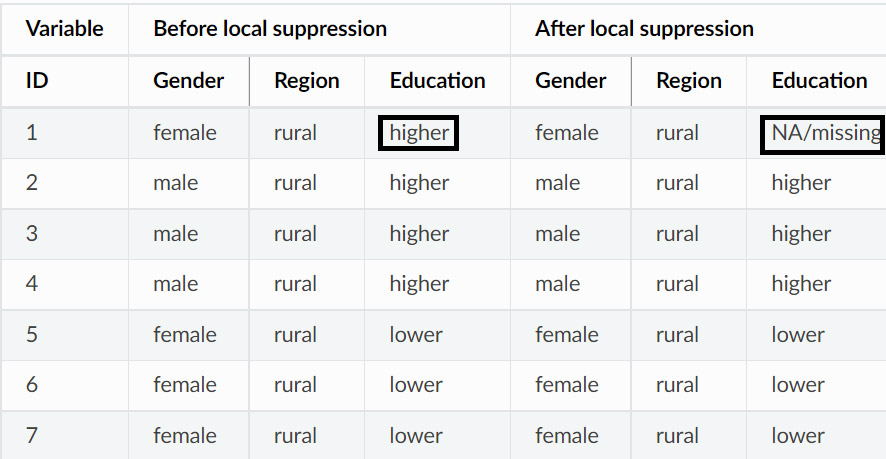
Source: Anonymization Methods
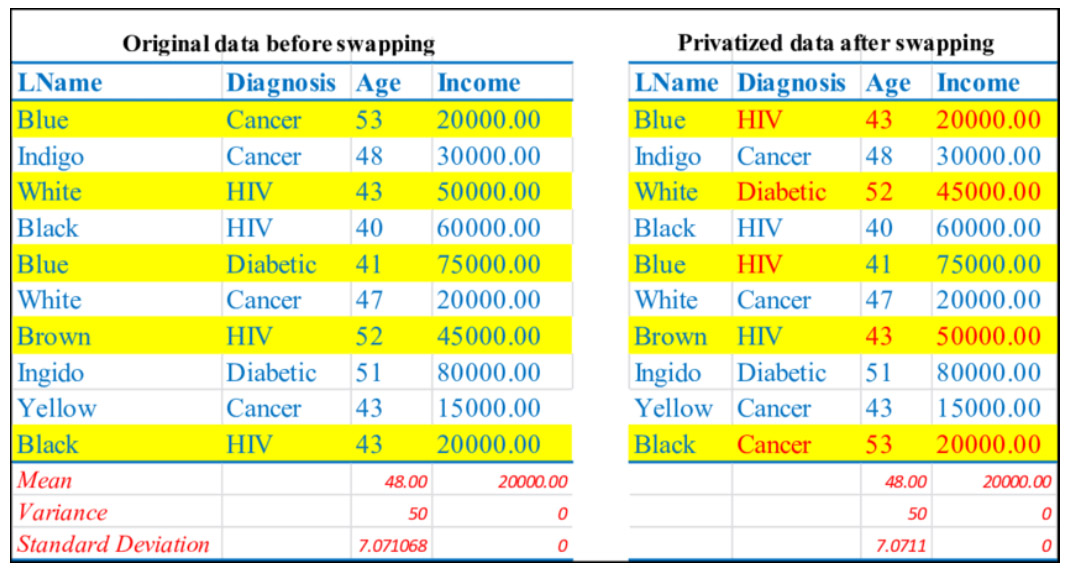
Masking
Masking is implemented by converting the personally identifiable information into a hash string.
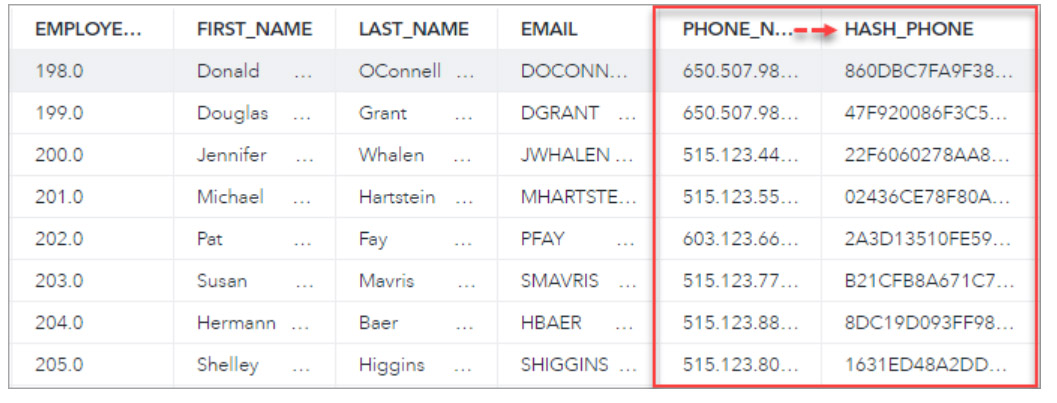
Source: SAS® Help Center
Generalisation
Generalisation replaces a specific value with a range, broadening the horizon. For instance, the age of 42 can be replaced with the range of 40-50.
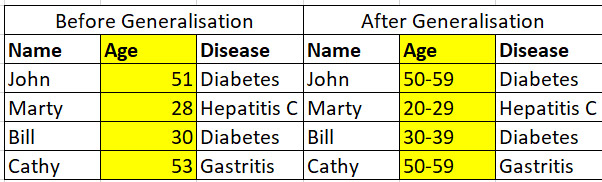
Source: Sciencedirect
Even though pseudonymisation as a technique has been around for some time, modern data scientists are divided on its sustained relevance in defending privacy. The concern is the fundamentally improvising nature of the Pseudonymisation methods and the lack of orderability around them.
While procedures like Suppression, Swapping, Masking, and Generalisation do get the job done, they are silent on gauging the level of privacy their application can ensure for process mining event logs.